Se usi Claude in modo intensivo, prima o poi ci arrivi: il messaggio di “limite raggiunto” a metà mattina, la sessione che si trascina lenta perché il contesto è diventato enorme, o il costo API che cresce senza che tu abbia prodotto proporzionalmente di più.
Non è un problema di quanto sei bravo a scrivere prompt. È un problema di come stai usando lo strumento. Ci sono abitudini che consumano token in modo silenzioso, e la maggior parte si correggono in cinque minuti.
Questa guida raccoglie le strategie più efficaci, organizzate per fase di lavoro.
Prima ancora di scrivere: le scelte che fanno più differenza
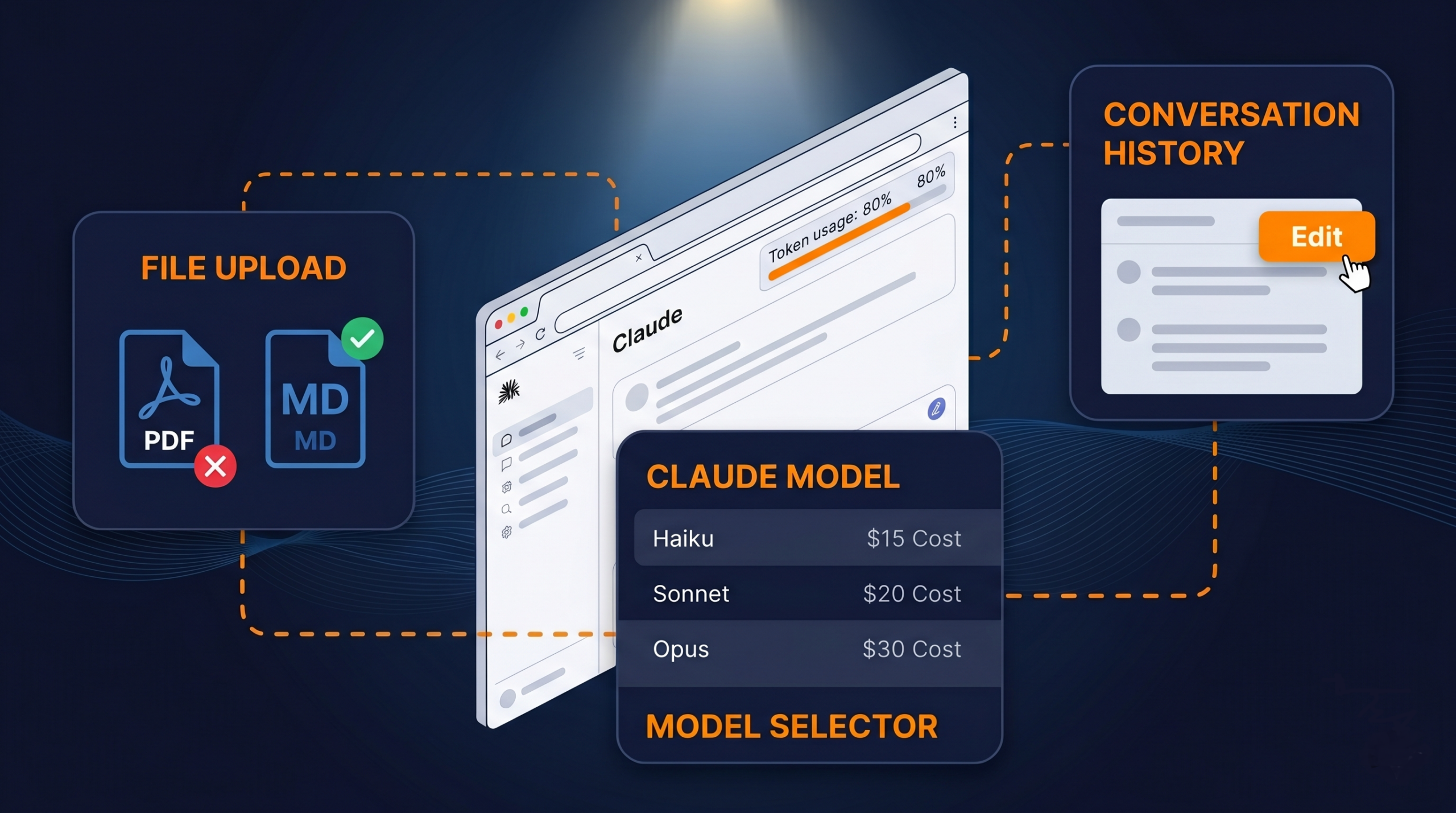
Scegli il modello giusto per ogni task
Usare Opus per tutto è come prendere un taxi per andare a comprare il pane. Haiku è velocissimo e costa pochissimo: va benissimo per bozze, revisioni rapide, domande semplici. Sonnet copre la maggior parte dei task tecnici e di scrittura. Opus ha senso solo quando il problema è genuinamente complesso e richiede ragionamento profondo.
La scelta del modello sbagliato non cambia solo il costo: cambia la velocità della sessione e, indirettamente, quante iterazioni riesci a fare.
Converti i file prima di caricarli
Caricare un PDF direttamente in Claude è uno dei modi più silenziosi per bruciare token. Una pagina PDF standard pesa tra 1.500 e 3.000 token, perché il modello deve processare la struttura del file oltre al contenuto. La stessa pagina estratta come testo in un file .md costa una frazione.
Se lavori spesso con documenti, vale la pena automatizzare questa estrazione. Un semplice script Python con pdfplumber o anche un copia-incolla manuale in un file Markdown prima del caricamento fa una differenza reale nel tempo.
Disattiva le funzionalità che non ti servono per quel task
Web search, connectors e Extended Thinking aggiungono token a ogni risposta, anche quando non stai usando attivamente quelle funzionalità. La logica corretta è tenerle disattivate per default e attivarle solo quando servono davvero. Non è una rinuncia alle funzionalità: è scegliere quando usarle invece di pagarle sempre.
Pianifica in chat, costruisci altrove
Per ragionare su un’idea, esplorare opzioni o strutturare un progetto, la chat è economica. Per produrre output definitivi complessi, strumenti come Cowork lavorano su finestre di contesto più efficienti. Usare la chat per il pensiero e strumenti dedicati per l’output finale riduce il costo complessivo senza rinunciare a nulla.
Durante la conversazione: i comportamenti che fanno la differenza
Istruisci Claude a fare domande prima di rispondere
Un prompt corto come “prima di rispondere, fammi le domande necessarie per capire bene cosa ti serve” può sembrare controintuitivo. In realtà evita il ciclo più costoso: risposta generica, correzione, risposta aggiornata, altra correzione.
Una singola sessione di chiarimento a 15 parole può eliminare tre o quattro scambi successivi. Sul lungo periodo, questo è uno dei cambiamenti più efficaci.
Raggruppa i task in un unico messaggio
Ogni volta che mandi un messaggio, Claude ricarica l’intero contesto della conversazione. Tre messaggi separati producono tre ricaricamenti completi. Un messaggio con tre task produce un solo ricaricamento.
Non è sempre possibile (a volte hai bisogno della risposta al punto 1 per formulare il punto 2), ma quando i task sono indipendenti, combinarli in un unico prompt è immediato e gratuito.
Modifica, non rispondere
Quando una risposta è quasi giusta ma manca qualcosa, l’istinto è scrivere un messaggio di follow-up. Ma ogni follow-up si appoggia su tutto il contesto precedente. Se invece modifichi il messaggio originale e lo reinvii, Claude ricomincia da quel punto senza accumulare la catena precedente.
Su Claude.ai esiste il tasto Edit direttamente sui messaggi. Usarlo quando ha senso riduce la lunghezza effettiva della sessione.
Specifica la sezione, non richiedere la riscrittura completa
“La sezione 3 non mi convince, riscrivila solo quella” è molto più efficiente di “riscrivi l’articolo”. L’output che Claude produce conta quanto l’input che elabora. Istruzioni chirurgiche producono output chirurgici, e il totale dei token consumati scende.
Dopo la sessione: abitudini che proteggono le sessioni future
Riassumi e riparte ogni 15-20 messaggi
Una sessione di 20 messaggi pesa circa 105.000 token. A 30 messaggi si arriva a 232.000. Non è solo una questione di costo: con un contesto così lungo, Claude rilegge ogni volta l’intera conversazione, e le risposte diventano più lente e meno precise.
La pratica corretta è: intorno ai 15-20 messaggi, chiedi a Claude di riassumere la conversazione in un paragrafo denso, copi il riassunto, apri una nuova chat e lo incolli come primo messaggio. Riparti da lì. Ci vogliono due minuti e mantieni tutta la continuità che ti serve.
Argomento nuovo: chat nuova
Tenere tutto in un’unica conversazione lunghissima sembra comodo. In realtà obbliga Claude a rileggere ogni volta contesti che non c’entrano con la domanda attuale. Una chat per argomento mantiene i contesti corti e le risposte più veloci.
Usa i Progetti per i file ricorrenti
Se hai file che riusi spesso (istruzioni di stile, documentazione di progetto, brief fissi), caricarli ogni volta in una nuova chat è un spreco. I Progetti in Claude.ai permettono di caricare questi file una volta sola: vengono referenziati in automatico in ogni nuova sessione senza ricaricarli.
Imposta le preferenze una volta sola
Ogni volta che inizi una chat spiegando come vuoi che Claude risponda (tono, formato, lingua, livello tecnico), stai pagando token di setup. Le preferenze e gli stili personalizzati nel profilo Claude eliminano questi messaggi di configurazione. Un setup iniziale, risparmi permanenti.
Una stima concreta
Non esistono numeri universali perché dipende da come usi Claude, ma l’ordine di grandezza è questo: combinare anche solo quattro o cinque delle pratiche sopra, nelle sessioni di lavoro tipiche di chi usa Claude per scrivere o sviluppare, riduce il consumo di token del 30-50% senza toccare la qualità dell’output.
La parte interessante è che alcune di queste pratiche, come raggruppare i task o usare Edit invece di Reply, migliorano anche la qualità delle risposte. Non è solo risparmio: è lavorare meglio.
In sintesi
Non serve cambiare tutto. Scegliere il modello giusto, convertire i PDF prima di caricarli, riassumere e ripartire ogni venti messaggi, e raggruppare i task quando puoi: questi quattro cambiamenti da soli coprono la maggior parte del potenziale di risparmio. Il resto si affina con il tempo.
Se stai ottimizzando il modo in cui lavori con Claude, può valere la pena allargare il quadro. Ho scritto di come l’AI sta cambiando concretamente il lavoro dello sviluppatore nel 2026: meno boilerplate, più decisioni, e qualche rischio che vale la pena conoscere. Se invece vuoi costruire prompt più efficaci a livello tecnico, la guida sul prompt engineering per API pulite parte proprio dal problema opposto: non come risparmiare token, ma come strutturare le istruzioni per ottenere output precisi al primo colpo. E se cerchi nuovi strumenti da aggiungere al tuo stack, la lista dei 10 tool AI per sviluppatori è un buon punto di partenza.
Per chi vuole andare più in fondo sul tema, la documentazione ufficiale di Anthropic sui modelli è il riferimento più aggiornato per confrontare costi e capacità di Haiku, Sonnet e Opus. Sul fronte della gestione del contesto, il post ufficiale sul context window spiega in dettaglio come Claude legge e pesa i token in una conversazione. Vale anche la pena leggere la guida al prompt engineering di Anthropic: non è teorica, ha esempi pratici che si collegano direttamente alle tecniche di questa guida.